Machine Learning Opportunities in Mobile Network Engineering
It is known about the importance of software, and it is not new that it is everywhere. It is already part of our world for so long. As we evolve, and systems, networks, or even social interactions get more complex, the demand continuously increases, a well-known trend for all in (and not only) the field of mobile communications. Hence, as more and more data is generated, it is essential to have algorithms allowing the computation of such an amount of information, reaching results, trends, and insights that would not be possible to get without them.
Machine Learning is nowadays one of the hot topics of computation, with a wide variety of applications, greatly contributing to the technological growth in any area. Since it is inevitable to find Machine Learning in every corner of the technological world, how could these methods be involved in the mobile communication industry in an effective manner? Mobile operators and planning & optimization engineers could benefit from the automation and insights given by Machine Learning applied to mobile networks.
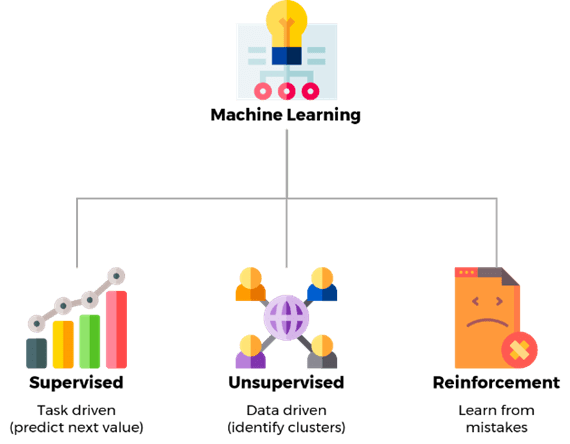
Machine Learning is a sub-area of artificial intelligence and computer science whose aim is to provide the machine with the capability of learning, using techniques that are similar to human behavior and the learning process. The algorithms learn from datasets and statistical models, to then perform predictions and classifications of data, which can bring useful and automated insights for a variety of applications. Machine Learning algorithms can be classified into three main types: Supervised Learning, Unsupervised Learning, and Reinforcement Learning.
Machine Learning Algorithm Types and Real-Life Applications
From a simple inbox spam detector to anomaly detection or recommendation systems, the three types of Machine Learning are widely used nowadays on a day-to-day basis. Naturally, they differ in the way the models learn, and so the applications use the one that adapts the best to the algorithm that best fits its purpose:
Supervised Learning: This is based on labelled datasets that teach (train) the model on how to accurately get the answers given a type of input. Classification and regression are two types of problems within this type of learning. The first is used to categorise data, the second uses regression models to provide predictions, based on the relationship between the input variables.
Real-life examples of this type of learning are e-mail spam detection, facial recognition systems both for privacy security and surveillance systems, and predictions, such as weather or prices.
Unsupervised Learning: With this, the system understands the trends, and patterns, and provides answers/classifications based on them and their attributes, without the need for human intervention (supervision). Through the learning algorithms, it analyzes the unlabelled data and finds patterns in the dataset, being useful for grouping data based on similarities of their attributes (clustering) or correlating attributes within the dataset (association).
In real life, we have Unsupervised Learning in recommendation systems, such as in video streaming services and online shopping, customer segmentation (marketing), or fraud detection, such as suspicious bank transactions.
Reinforcement Learning: The learning in this type is done based on a feedback loop, where the model is improved through trial and error, with a reward system that guides it through the right path. So, the learning of what is right and wrong is based on reward and punishment, respectively. The aim of these models is to maximise the results by iteration.
This challenging Machine Learning approach is being applied in several applications, including autonomous systems (e.g., self-driving cars or robot vacuum cleaners), healthcare, namely in dynamic treatment regimens or automated medical diagnosis, or gaming, where these models simplify the traditional way of creating video games (behaviour learning according to the game environment and goals, instead of a more fixed and complex behavioural tree).
Use Cases of Machine Learning in Mobile Network Engineering
With the development and increasing adoption of Self-Organising Networks (SON) solutions, Machine Learning is naturally on the road to evolving in the telecommunications industry and helping mobile operators giving a step forward, improving the engineering processes and the network performance. It is unquestionable the added value and benefits these solutions bring to the mobile operators, which, in the end, leads to a better end-user experience and in a better performing and resilient network.
As for Machine Learning, and considering its main types of algorithms, it is possible to list some of the use cases that could be applied to the daily life of a mobile operator, easing the work of mobile network engineers, bringing efficiencies and maximising resources:
Intelligent Performance & Configuration Alarmistic System
There is a significant number of network events which can lead to service degradations, reflected in the network Key Performance Indicators (KPIs), but it is not always easy to keep a detailed track of all abnormal issues responsible for peaks of failures in a short amount of time, or other unusual degradations. Sometimes, actively identifying an issue in a single cell, over a network of thousands of cells, could be challenging, if the main KPIs are not perceptively affected. Anyway, the problem still exists, and it can impact the performance in a specific area. On the other hand, a misconfiguration of the network parameters can lead to a negative impact, affecting the user experience and, ultimately, the operator’s revenue.
The Intelligent Performance Alarmistic System model would be based on Unsupervised Learning to actively identify abnormal behaviours on the network, both in terms of statistics and configuration. The system would use the statistical and configuration data as inputs and would work with it to identify outliers. For example, if certain KPIs/counters abruptly change, or if they start having an uncommon trend, the system will create an alert for the engineers to check. Similarly, if a parameter change occurs out of the usual values, or on the most common ranges, an alert would be also given, so the engineers could confirm if that value was supposed or not.
The functionality would allow for quickly identifying network degradations at a detailed level, such as cell–level, which would traditionally be possible through continuous follow-up of all cells and KPIs, which is unpractical. Additionally, it would detect specific degradations usually not detected in the general network monitoring KPIs, given the weight of a single cell. And if several cells degrade, the system can detect them as well in a fast way. The same for the configuration part, where errors or improper configurations can be rapidly detected, minimising the impact on the network performance. As a drawback, the accuracy would need to be refined, since false alarms would need to be avoided as much as possible.
Network Troubleshooting Insights
The optimisation of a mobile network is not a process where an engineer can simply follow a recipe. It depends on the issue, the causes, and several variables that can influence and change the course of troubleshooting. However, network counters help the engineers identify the causes of a KPI degradation, so then they can focus on it and reach the appropriate solution. Working as a guide, these counters are commonly used in the troubleshooting process, being one of the basics of network problem-solving, and their behaviour provides useful insights to the engineers.
The Network Troubleshooting Insight model would make use of Supervised Learning to categorise several types of network issues based on a set of attributes, i.e., a set of network performance counters. This way, the model would be trained with a dataset based on the engineer’s knowledge and experience, correlating groups of counters with causes, so it could accurately identify the main issues of the network and provide the user with the probable detailed reason for the problem. If the configuration part was added to this algorithm, a more advanced system would be created, where the settings could be crossed with statistics, so to identify possible misconfigurations.
In addition to the previous functionality, this system could also provide suggestions of possible actions to take given a particular reason. Assuming the actions performed by the engineers are registered on a platform, the model takes this data, crosses it with the network statistics (and configuration) prior to the changes, and works on it to associate problems with the solutions. This would be achieved through Unsupervised Learning.
Hence, an operator with this function would most benefit in terms of efficiency, as the engineers would save time both in the troubleshooting and optimisation, which can have an impact on the user experience, since the time for the issue resolution would decrease.
Configuration-based KPI Maximisation
To provide the best service to the customers and have a high-performing network, mobile operators aim for certain target KPIs. As a natural process, if some of the defined KPIs are below the target, the aim is to work on the network so the KPI could fulfil its value. There could be several reasons for the KPI to be below the target, but one way of getting it on target can be through network parameter configuration. Given the nature of the network vendor’s structure, where a lot of parameters can influence several KPIs (positively or negatively), finding the best settings can be challenging sometimes. The tuning of these parameters is iterative and can involve a lot of steps, performance analysis, and changes going back and forth.
Ideally, a Configuration-based KPI Maximization model would suppress the need for manual tuning, since a set of parameters would be put to test, with the system using Reinforcement Learning to put a certain KPI (or KPIs) above a given value. As a trial-and-error procedure, the set of defined parameters would be trialled on their possible values, as well as combinations with each other, with the reward being the KPI value – the higher the value, the better. In the end, the result would be the ideal settings of the network parameters to maximise the KPI.
However, this kind of trial-and-error algorithm would not be suitable to be first put on the live network, as the system would get unsuccessful configurations before reaching an optimal solution in the iterative process, i.e., this would only be considered for the live network when the model reached a stable and accurate state. To overcome this, a possibility would be replicating the network (or part of it), on a simulator, or running the algorithm in the lab. One of the drawbacks is the lack of data to tune the model itself. Anyway, a lab environment could help in understanding what the best parameter settings would be to improve a given KPI. A similar idea was tested at AT&T labs: a Reinforcement Learning algorithm was used in a lab environment with the aim of reaching the optimal eNodeB MAC scheduler configuration, using the spectral efficiency and the gap between UE’s throughput as rewards (balancing between throughput and fairness). This study proved the effectiveness of applying this type of algorithm to improve network performance. It has several challenges, but it is surely a solution to consider for the future.
A similar idea was tested at AT&T labs: a Reinforcement Learning algorithm was used in a lab environment with the aim of reaching the optimal eNodeB MAC scheduler configuration, using the spectral efficiency and the gap between UE’s throughput as rewards (balancing between throughput and fairness). This study proved the effectiveness of applying this type of algorithm to improve network performance. It has several challenges, but it is surely a solution to consider for the future.
Traffic Predictions
The network behaviour varies throughout the year, depending on the season, specific dates, or events. As time goes by and new technologies are introduced, the network profile changes as well, and the operators cannot take as granted the traffic profile from previous periods. Thus, accurate traffic predictions are of foremost importance for a mobile operator, as based on it the strategy can be drawn, and future needs and solutions can be anticipated, with great impact on the company’s operations.
Machine Learning can also bring solutions for traffic trend predictions and help the mobile operator forecast future network behaviour. For this, similarly to the methods used in weather and price predictions, the model would be based on Supervised Learning, where a regression would be used to predict future trends based on past data. As a drawback, this method might not be able to predict new trends if a completely new technology is involved, or if some abnormal event occurs, such as a pandemic, given the (lack of) accurate historical data. For instance, during a pandemic, the traffic profiles change, so those would influence the prediction of the following years if not enough data is obtained from previous years. Despite the challenges, there are Mobile Operators working on this kind of solution for traffic prediction.
Drive Test Analysis Classification
The post-processing of a Drive Test usually involves the analysis of occurred events, which can point out areas of possible poor experience for the user. Drive Test processing tools can provide the engineers with a list of all the events that occurred, detailed with a set of attributes that describe the conditions during the event occurrence. With this, the engineer can have an idea of the main aspects that could have led to that event and then check in more detail in the Drive Test logs for the problem, so they can then provide a solution. In the analysis process, the events are usually associated with a cause (e.g., transmission, poor coverage, interference, capacity) and the proposals are in that scope. Handling this is sometimes time-consuming, as it involves a significant amount of data, especially if there are a lot of events.
Hence, given past data from previous analysis manually performed, it would be possible to use it as labelled data (classification), so in future analysis, the events would be categorised according to the possible cause, giving a first insight into the possible problems. For example, if an event occurred with certain attributes, such as low SINR and good RSRP, a probable reason could be interference.
This would allow the engineers to have a first insight on what would be the cause, so they could then focus on that in the analysis, saving time in the first categorisation. The model could go further and present possible optimisation actions, correlating past analysis issues and respective actions taken.
Conclusion
It is a fact that Machine Learning is here to stay and be a strong ally in technological development, given the increasing amount of data to process and analyse. It is proven that it is widely spread across several areas, in the most common applications of people’s daily lives, and that it can be as well widely adopted in mobile network engineering, given the range of opportunities, and the technological resources available, despite all its challenges.
Undoubtedly, Machine Learning can bring high value to Mobile Communications, as it is already observed with its involvement in SON solutions, but there is still a lot of room for improvement. Hence, the investment from the market’s key players in these models is paramount as a strategy for a future-proof solution, increasing efficiency, bringing new opportunities, and adding value to the market.
One can also ask if artificial intelligence can replace an optimisation engineer in the future; it might not replace it completely, but it can make their work better, and simplified and give room to other areas where they can focus, such as the automation itself. This highlights the importance of softwareawareness from the telecom engineering field since more and more automation will be part of this world.
References
[1] Chen,Y., Chen,J., Krishnamurthi,G., Yang,H., Wang,H. and Zhao,W., “Deep Reinforcement Learning for RAN Optimization and Control”, IEEE Wireless Communications and Networking Conference (WCNC), Mar. – Apr. 2021 (https://arxiv.org/pdf/2011.04607.pdf ).
MWC Barcelona 2026 once again brought together the global telecom community to explore the technologies shaping the next decade of connectivity. This year’s event (2–5 March) placed a strong spotlight on AI-native networks, automation at scale, and the operational transformation required to support increasingly complex, multi-vendor, multi-cloud environments. NEC Aspire Technology returned to Barcelona with […]
In July 2025, Aspire was granted a US patent for its innovative method to accurately quantify sellable capacity in Fixed Wireless Access (FWA) networks. As operators accelerate 4G & 5G FWA rollouts, a key challenge is determining how many additional subscribers can be added per sector without degrading service performance. Aspire patented method addresses this […]
In a year defined by rapid advances in AI and automation, one thing remains constant: people are still at the heart of meaning, purpose, and success. At Aspire, that includes not only our teams, but also the clients and partners we work alongside every day. Because in our world, business isn’t just technical – it’s […]
At this time of year, the calendar is traditionally packed with regional IEEE events and Aspire was proud to contribute to two of the most significant gatherings in Serbia. The TELSIKS 2025 conference, held in Niš, Serbia, from 22–24 October, provided an excellent platform for presenting our latest research. Uroš Savković and Igor Tomić represented NEC Aspire Technology with their paper on Advanced Spectral Efficiency...
At NEC Aspire Technology, we’ve always believed that excellence is earned through action and recognized through impact. That’s why we’re proud to share a major milestone in our journey: Aspire has become the first 100% qualified service partner for Oracle Communications Unified Assurance (OCUA). This distinction reflects more than just technical certification. It’s a recognition of our proven […]
We use cookies on our website to give you the most relevant experience by remembering your preferences and repeat visits. By clicking “Accept”, you consent to the use of ALL the cookies. However you may visit Cookie Settings to provide a controlled consent. Privacy Policy
This website uses cookies to improve your experience while you navigate through the website. Out of these cookies, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may have an effect on your browsing experience.
Cookie
Type
Duration
Description
bcookie
0
2 years
This cookie is set by linkedIn. The purpose of the cookie is to enable LinkedIn functionalities on the page.
bscookie
1
2 years
cli_user_preference
session
1 hour
The cookie is used to store the yes/no selection the consent given for cookie usage. It does not store any personal data.
cookielawinfo-checkbox-advertisement
0
1 year
This cookie is set by GDPR Cookie Consent plugin. The purpose of this cookie is to check whether or not the user has given their consent to the usage of cookies under the category 'Advertisement'.
cookielawinfo-checkbox-analytics
0
1 year
This cookie is set by GDPR Cookie Consent plugin. The purpose of this cookie is to check whether or not the user has given the consent to the usage of cookies under the category 'Analytics'.
cookielawinfo-checkbox-functional
0
1 year
cookielawinfo-checkbox-necessary
0
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookies is used to store the user consent for the cookies in the category "Necessary".
cookielawinfo-checkbox-non-necessary
0
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookies is used to store the user consent for the cookies in the category "Non Necessary".
cookielawinfo-checkbox-performance
0
1 year
This cookie is set by GDPR Cookie Consent plugin. The purpose of this cookie is to check whether or not the user has given the consent to the usage of cookies under the category 'Performance'.
cookielawinfo-checkbox-preferences
0
1 year
This cookie is set by GDPR Cookie Consent plugin. The purpose of this cookie is to check whether or not the user has given the consent to the usage of cookies under the category 'Preferences'.
fpestid
0
1 year
Fpestid is a ShareThis cookie ID set in the domain of the website operator.
GPS
0
30 minutes
This cookie is set by Youtube and registers a unique ID for tracking users based on their geographical location
hubspotutk
0
1 year
This cookie is used by hubspot to keep track of the visitors to the website. This cookie is passed to Hubspot on form submission and used when deduplicating contacts.
IDE
1
2 years
Used by Google DoubleClick and stores information about how the user uses the website and any other advertisement before visiting the website. This is used to present users with ads that are relevant to them according to the user profile.
lang
0
This cookie is used to store the language preferences of a user to serve up content in that stored language the next time user visit the website.
lidc
0
1 day
This cookie is set by LinkedIn and used for routing.
lissc
0
1 year
Used to ensure there is correct SameSite attribute for all cookies in that browser.
li_gc
0
30 minutes
Used to store consent of guests regarding the use of cookies for non-essential purposes
li_sugr
0
2 months
rtc
0
1 month
Used as part of anti-abuse processes on LinkedIn
test_cookie
0
11 months
u
0
2 months
UserMatchHistory
0
4 weeks
viewed_cookie_policy
0
11 months
The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies. It does not store any personal data.
VISITOR_INFO1_LIVE
1
5 months
This cookie is set by Youtube. Used to track the information of the embedded YouTube videos on a website.
YSC
1
This cookies is set by Youtube and is used to track the views of embedded videos.
_ga
0
2 years
This cookie is installed by Google Analytics. The cookie is used to calculate visitor, session, camapign data and keep track of site usage for the site's analytics report. The cookies store information anonymously and assigns a randoly generated number to identify unique visitors.
_gat_gtag_UA_131216975_1
0
1 minute
Google uses this cookie to distinguish users.
_gid
0
1 day
This cookie is installed by Google Analytics. The cookie is used to store information of how visitors use a website and helps in creating an analytics report of how the wbsite is doing. The data collected including the number visitors, the source where they have come from, and the pages viisted in an anonymous form.
__cfduid
0
3 months
Cookie associated with sites using CloudFlare, used to speed up page load times. According to CloudFlare it is used to override any security restrictions based on the IP address the visitor is coming from. It does not contain any user identification information.
__hssc
0
30 minutes
__hssrc
0
__hstc
0
1 year
__stid
0
1 year
The cookie is set by ShareThis. The cookie is used for site analytics to determine the pages visited, the amount of time spent, etc.
__stidv
0
1 year
The cookie is set by ShareThis. The cookie is used for site analytics to determine the pages visited, the amount of time spent, etc.
Necessary cookies are absolutely essential for the website to function properly. This category only includes cookies that ensures basic functionalities and security features of the website. These cookies do not store any personal information.
Any cookies that may not be particularly necessary for the website to function and is used specifically to collect user personal data via analytics, ads, other embedded contents are termed as non-necessary cookies. It is mandatory to procure user consent prior to running these cookies on your website.
Analytical cookies are used to understand how visitors interact with the website. These cookies help provide information on metrics the number of visitors, bounce rate, traffic source, etc.
Advertisement cookies are used to provide visitors with relevant ads and marketing campaigns. These cookies track visitors across websites and collect information to provide customized ads.
Performance cookies are used to understand and analyze the key performance indexes of the website which helps in delivering a better user experience for the visitors.
Functional cookies help to perform certain functionalities like sharing the content of the website on social media platforms, collect feedbacks, and other third-party features.